为 vLLM-Ascend 实现节点级 CPU Prefix Cache——设计、实现与踩坑记录
为什么需要 CPU Prefix Cache
大模型推理服务有几个关键指标:首 token 延迟(TTFT)、系统吞吐(QPS)、单位请求成本。在真实业务中,用户请求之间存在大量可复用的公共前缀——系统提示词、工具调用模板、多轮对话历史、RAG 检索结果、批量任务中的相同输入片段。如果能把这些前缀的 KV Cache 缓存起来复用,就可以跳过重复的 prefill 计算,直接降低 TTFT、提升吞吐。
vLLM V1 已经支持同节点内 HBM Prefix Cache 的复用,但问题在于:昇腾 NPU 的 HBM 是极其紧缺的资源。模型权重加载完后,留给 KV Cache 的空间很有限;在长上下文、高并发、大 batch 场景下,HBM KV Cache 很快会被活跃请求占满,能长期保留的 Prefix Cache 空间严重不足。所以 HBM Prefix Cache 虽然快,但在生产场景中容量受限,很难形成稳定有效的缓存命中。
那么很自然的想法就是——把 CPU DRAM 用起来。CPU 内存容量大、成本低,虽然访问速度不如 HBM,但适合保存那些访问频率相对较低、但仍然有复用价值的 Prefix KV Cache。通过异步将 KV Cache 从 HBM 搬运到 CPU DRAM,后续请求命中时再按需回迁,在不增加 HBM 常驻压力的前提下扩大 Prefix Cache 的可复用范围。
这就是我们做 CPU Offloading 的出发点。
几个关键设计决策
在动手之前,我们定了几个基本约束,这些约束直接影响了后续的架构选择。
节点级共享,不跨节点
CPU DRAM Prefix Cache 的共享范围是单节点。不同物理节点之间不共享,但同一节点内不同 DP 域之间可以共享。这个设计天然要求一个前提:同一个 DP 域内的 Worker 必须部署在同一物理节点上。如果 Worker 跨节点分布,同一请求依赖的 KV Cache 就会分散在不同节点,引入跨节点拉取、缓存一致性维护和额外网络开销,得不偿失。
所以我们在部署层面将 DP 域和节点边界绑定——每个 DP 域内的 Worker 位于同一节点,CPU DRAM Prefix Cache 作为节点内部的共享缓存层。
低侵入式设计,复用 KVConnector 架构
vLLM V1 提供了 KVConnectorBase_V1 抽象基类和 KVConnectorModelRunnerMixin,这给了我们一个很好的扩展点。我们的目标是:对 Scheduler 和 Worker 原生代码零改动,CPU Offloading 逻辑全部封装在 Connector 模块和配套的 MetadataServer 进程中。
这样做的好处很明显:不影响 vLLM 主体执行流程、方便独立维护和开关控制、后续版本升级的适配成本也更低。
异步逐层 swap-out,不阻塞主推理路径
在 prefill 过程中,每层生成新的 KV Cache 后立即触发异步拷贝到 CPU DRAM,让数据搬运与后续层的 forward 计算形成流水重叠,而不是等全部 forward 结束后集中搬运。不过,forward 结束后 Worker 主线程仍然需要同步等待所有层的 swap-out 完成——这是为了保证 CPU DRAM 中的数据完整可用,避免后续请求命中到写了一半的缓存。
命中增益阈值,避免”亏本”的 swap-in
从 CPU DRAM 回迁 KV Cache 到 HBM 是有开销的。如果 CPU 命中的前缀只比 HBM 多一点点,数据搬运的代价可能超过跳过的 prefill 收益。所以我们引入了一个阈值 k:
1 | CPU DRAM 命中长度 - HBM 命中长度 >= k |
只有满足这个条件才触发 swap-in。阈值可以按模型、上下文长度、业务负载和硬件配置灵活调整,在命中收益和搬运开销之间取得平衡。
整体架构
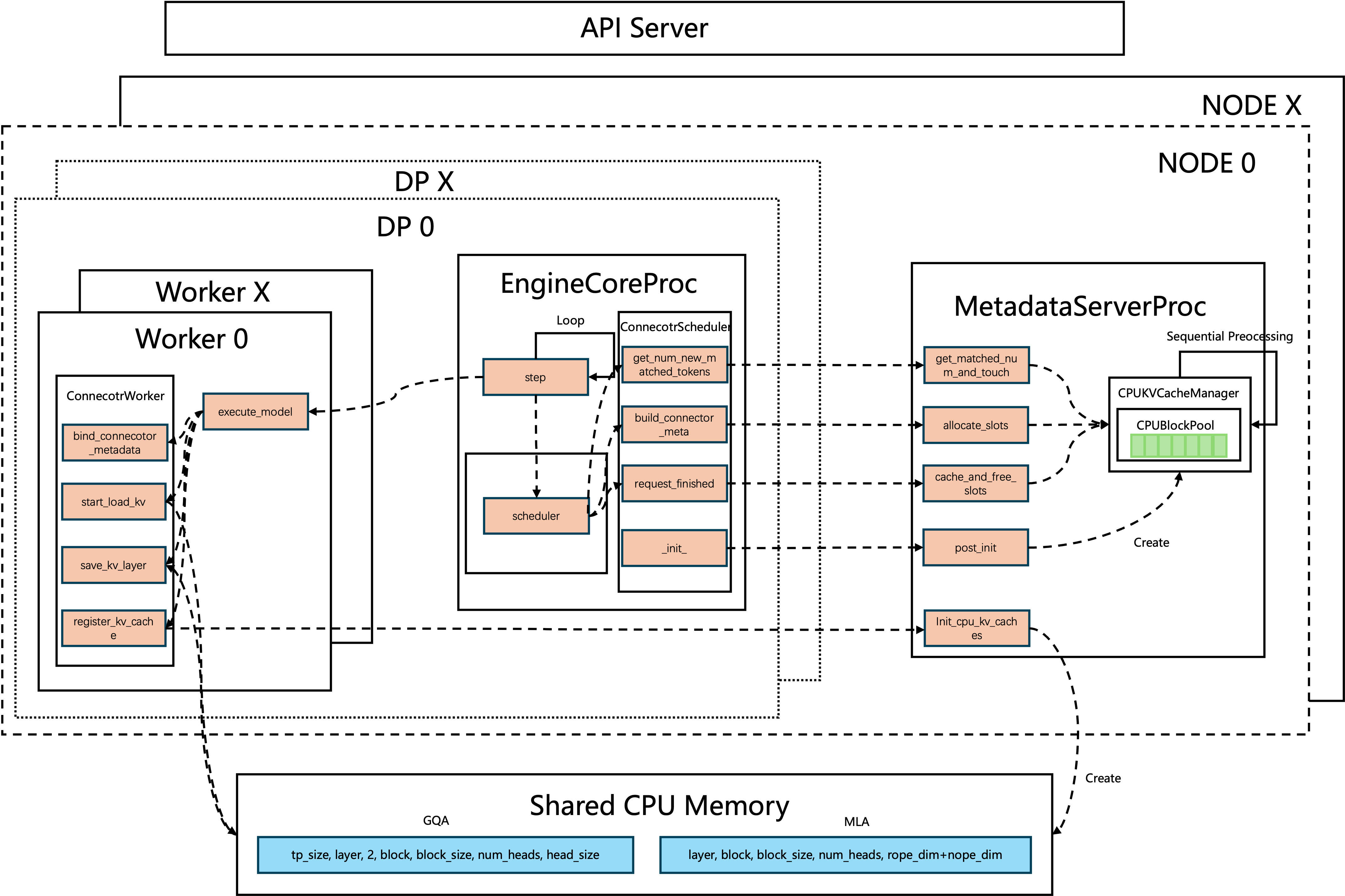
架构的核心思路是”控制面与数据面分离”:
- 控制面(Scheduler + MetadataServer):负责缓存匹配、空间分配、元信息构造和缓存生命周期管理。
- 数据面(Worker + NPU copy stream):只根据元信息执行实际的数据搬运,不参与缓存哈希和 block 管理。
我们在每个节点上启动一个独立的 MetadataServer 进程,管理共享 CPU KV Cache 空间、block 分配、哈希索引、引用计数和命中统计;新增的 CPUOffloadingConnector 则嵌入在 vLLM V1 的 KVConnector 扩展点中,对上层 Scheduler 和 Worker 保持透明。
Scheduler 侧和 Worker 侧各暴露 3 个接口:
| 侧 | 接口 | 职责 |
|---|---|---|
| Scheduler | get_num_new_matched_tokens |
查询 CPU DRAM 命中长度 |
| Scheduler | build_connector_meta |
构造本轮调度元信息(CPU block 分配、GPU block 映射等) |
| Worker | bind_connector_metadata |
绑定 Scheduler 下发的缓存元信息 |
| Worker | start_load_kv |
启动 DRAM → HBM 的 KV Cache 加载 |
| Worker | wait_for_layer_load |
每层 forward 前等待当前层加载完成,触发下一层加载 |
这样 Scheduler 只管”查缓存、分配空间、构造元信息”,Worker 只管”按元信息搬运数据”,MetadataServer 管”全局共享内存和缓存生命周期”,三个角色的职责非常清晰。
核心实现
MetadataServer:节点级的缓存大脑
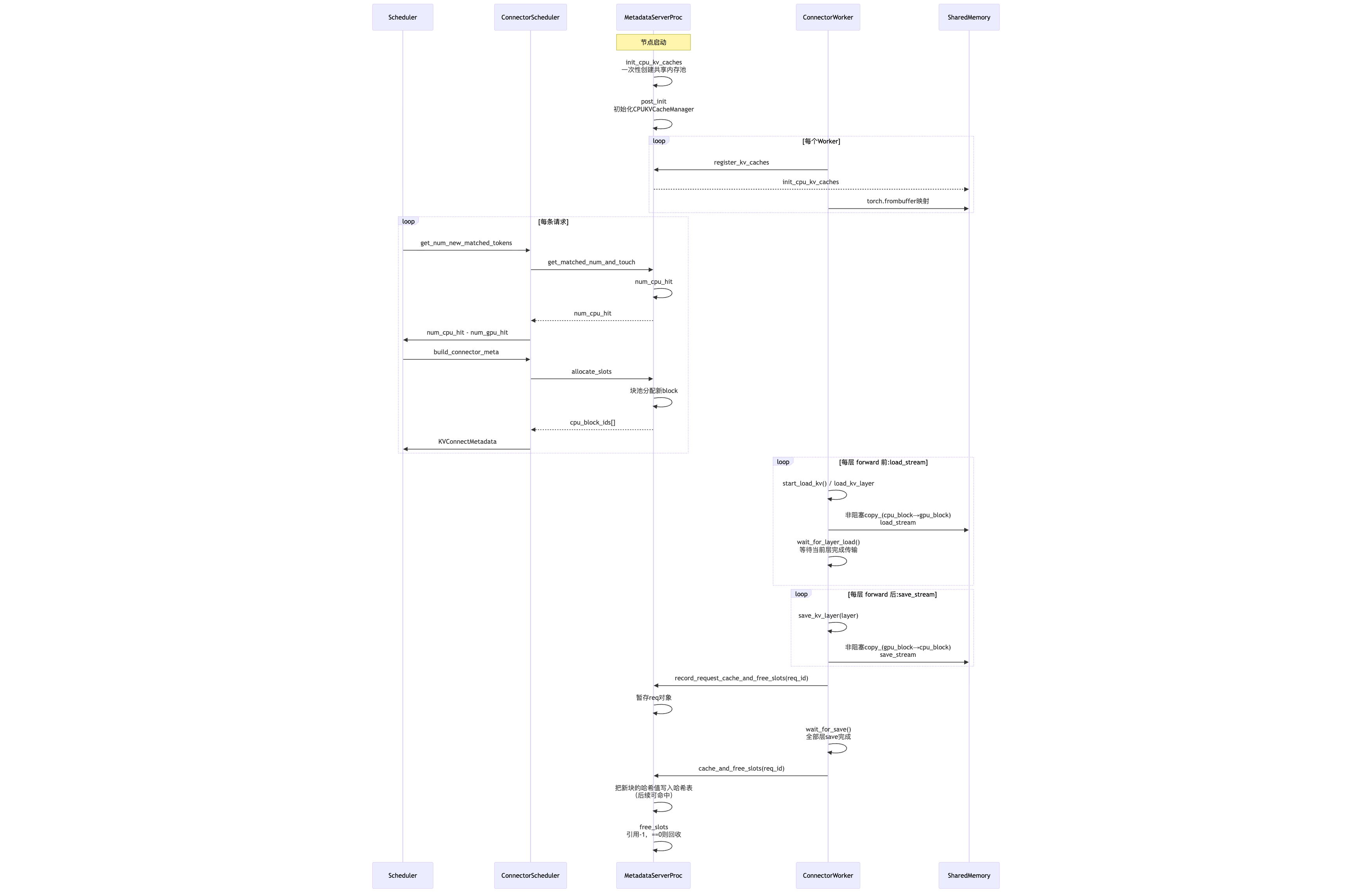
MetadataServer 是每个物理节点上唯一的控制进程(metadata_server.py),启动时根据 cpu_swap_space_gb 配置一次性创建共享内存池(默认 800 GB),统一管理本节点内的 CPU KV Cache 空间。
它对外暴露六个核心接口,配合完成缓存的全生命周期管理:
init_cpu_kv_caches:每个 ConnectorWorker 启动时调用,以(pp_rank, tp_rank)为维度初始化共享内存视图。首次出现的组合创建共享内存,已存在的直接复用,保证同节点内相同并行配置的 Worker 共享一致的缓存空间。post_init:全部 Worker 初始化完成后由 ConnectorScheduler 触发,整个节点生命周期内只执行一次,实例化CPUKVCacheManager并注册 RPC 路由表。get_matched_num_and_touch:调度前查询命中长度,同时对命中 block 增加引用计数,防止在 swap-in 完成前被提前回收。allocate_slots/cache_and_free_slots:两阶段缓存提交机制。allocate_slots只分配空间但不标记可用;等 Worker 侧 save 线程完成数据拷贝后,cache_and_free_slots才将 block 写入哈希表成为可命中缓存。这保证了后续请求永远不会命中写入未完成的脏数据。free_slot:请求结束时引用计数减一,降到 0 才真正回收。正确处理了多请求复用、提前 abort、新分配未提交等边界场景。
这里有两个我觉得值得展开的细节。
两阶段提交
为什么要把分配和标记拆成两步?因为在 allocate_slots 执行时,Worker 侧还没开始做 HBM → DRAM 的拷贝,CPU DRAM 里的数据是无效的。如果这时候就把 block 标记为可命中,后续请求命中后读到的是垃圾数据,推理就错了。所以必须等 Worker 后台 save 线程完成拷贝、通过完成队列通知 Metadata 后,才能把 block 写入 Prefix Cache 哈希表。
1 | # allocate_slots: 只分配,不标记 |
这个设计保证了 Prefix Cache 的一致性:只有完成数据写入的 block 才允许被命中。
引用计数保障生命周期安全
节点级共享 Prefix Cache 意味着多个请求可能同时引用同一段缓存。引用计数机制保证了:
- 同一段 Prefix Cache 被多个请求复用时,每个请求持有各自的引用;
- 某个请求提前 abort,不影响其他还在使用该缓存的请求;
- 新分配但尚未提交为 Prefix Cache 的 block 也有初始引用计数;
- 只有引用计数归零,block 才被回收到 pool。
CPUOffloadingWorker:数据搬运的流水线
数据搬运是 CPU Offloading 的数据面核心,有两类路径:DRAM → HBM(swap-in)和 HBM → DRAM(swap-out)。为了不让数据搬运阻塞模型计算,我们为 load 和 save 分别创建了独立的 NPU stream。
Swap-in:逐层加载,降低 TTFT 影响
当请求命中 CPU DRAM Prefix Cache 且命中增益超过阈值后,需要把命中的 KV Cache 从 CPU DRAM 回迁到 NPU HBM。如果等所有层的 KV Cache 全部加载完再开始 forward,TTFT 会被严重拖累。
我们的做法是逐层流水线加载:
1 | def start_load_kv(self) -> None: |
执行流程变成:
- 发起第 0 层 KV 加载
- 等待第 0 层完成 → 执行第 0 层 forward → 发起第 1 层加载
- 等待第 1 层完成 → 执行第 1 层 forward → 发起第 2 层加载
- …
这样只要求当前即将计算的层的 KV Cache 已经就位,不必等所有层一次性回迁完毕,大幅降低了集中式 swap-in 的前置等待时间。
当前实现用
self.load_stream.synchronize()做同步,后续可以换成torch.npu.current_stream().wait_stream(self.load_stream),避免不必要的全流同步,进一步降低开销。
Swap-out:后台线程 + 独立流,不阻塞主路径
Swap-out 用来把新生成的 KV Cache 保存到 CPU DRAM。为了避免阻塞 Worker 主线程,我们在 Connector 初始化时启动一个后台 save 线程,监听 save_input_queue:
- Worker 主线程提交待保存请求到队列
- 后台线程计算本次新增需保存的 block 范围
- 在独立
save_stream上异步执行 HBM → DRAM copy - 同步等待拷贝完成
- 将
req_id写入save_output_queue - MetadataServer 标记对应 block 为可复用
计算增量 block 范围的逻辑:
1 | for i in range( |
这样只保存新增产生且尚未写入 CPU 的 block,避免重复搬运。
MLA 与非 MLA 的适配
MLA 和非 MLA 模型在张量并行下的 KV Cache 组织方式不同,需要在保存时分别处理:
1 | if self.use_mla: |
MLA 场景下不同 TP rank 分担保存任务,减少搬运量和存储冗余;非 MLA 场景按完整映射保存,保证后续复用的正确性。这样 DeepSeek 等 MLA 模型和 Qwen 等 GQA/MHA 模型都能统一支持。
进程间通信:为什么我们手写了基于 ZMQ 的 RPC
实现跨 DP 域的 Prefix Cache 共享,block 查询和分配就必然需要跨进程通信。
vllm/distributed/device_communicators/shm_broadcast.py 里有一个基于 ZMQ 封装的 MessageQueue 类,支持一对多的广播调用和返回值收集。但我们的场景是多对一(多个 worker/scheduler 作为 Writer 调用 metadata 并收集返回值),直接复用会踩两个坑:
- 需要开多个独立 MessageQueue,overhead 变大;
- 主进程拉起 EngineCore 子进程时,busy loop 的参数无法通过
mp传递 MessageQueue 结构体(里面带有 socket 等不可序列化对象)。
考虑了三种方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| Pyro5 RPC 框架 | 代码少 | 新增依赖,性能不如 ZMQ |
| 强行复用 MessageQueue | 代码少 | 逻辑绕,每个 EngineCore 都要开独立 queue |
| 手写基于 ZMQ 的通信 | 性能高,定制灵活 | 工作量稍大 |
最终选了方案 3,复用了 vllm.utils.make_zmq_socket 来减少冗余。多对一 + 中心化 server 串行处理的模式恰好对应 zmq.ROUTER 和 zmq.DEALER,不需要手动在 server 侧实现 task 队列。
共享内存的坑
最初想用 pin_memory + share_memory_() 来开辟共享内存:
1 | def create_shared_pinned_tensor(): |
但实测发现通过 ZMQ + pickle 跨进程传输时,不同进程拿到的地址不同,怀疑每次都在新开辟空间。换用 multiprocessing.SharedMemory 后才正常工作:
1 | from multiprocessing.shared_memory import SharedMemory |
清理也要注意——Linux 下会在 /dev/shm 生成临时文件,必须在 client 端 shm.close() 后在 server 端 shm.close() + shm.unlink()。为了防止清理不干净或被残留文件影响,创建时加了保护:
1 | def _safe_create_shared_memory(name: str, size: int) -> SharedMemory: |
一个隐蔽的 bug:profile_run() 的显存估算
开启 KVConnector 后在特定大并发场景下会稳定卡住或爆显存。排查发现 profile_run() 估算的剩余可用显存反而比不开时更大,导致 GPU KV Cache 多分配,最终爆显存但表现是卡住。修复是将逻辑中的 is_kv_consumer 改为 not is_kv_producer,让显存估算与实际 KV Cache 消费行为对齐。
怎么测试:构造可控命中率的数据集
vLLM 的原生 benchmark 无法构造复杂命中率数据,所以我们自己设计了一套方法。
采用三段式数据格式:所有请求共用 common prefix + 同组请求共用 group prefix + 各自 random data。命中率统计最近 1k 条请求,KV Cache block 大小为 128。通过修改 benchmark_serving.py 增加三种重复发送模式来控制命中率:
- sequential:将请求按顺序再发一遍,模拟连续访问相同数据。
- stack:倒序再发一遍,模拟反向访问。
- reverse:按奇偶拆分,结合
num_group控制相同前缀的 req 每组两个,可以控制 GPU 开始驱逐时的命中率。
举例来说:common prefix 1024、group prefix 1024、random data len 2048,1k 条请求每组 512 个——这时 GPU 命中率为 25%,但 HBM 容量不够导致 group prefix 被驱逐,而 DRAM 空间充足,每组的 group prefix 都能在 CPU 上命中,CPU 命中率 12.5%。调整这些参数和发送格式,可以构造多种命中率组合来测试。
效果如何
在 DeepSeek 上开启 CPU Offload 后基本没有性能损失,命中率越高收益越大。以 37.5% CPU 命中率为例,相比纯 GPU prefix-cache:
| 命中场景 | 吞吐收益 |
|---|---|
| 纯 GPU 命中 | -2.336% |
| 37.5% CPU 命中 | +22.64% |
| 混合命中 | +11.229% |
此外,在测试过程中通过 profiling 发现了一个值得关注的性能细节:GQA KV Cache 在 prefix 命中场景下,调用的算子性能较差,部分算子的执行时间明显长于预期。这提示在 GQA 模型上开启 Prefix Cache 时,除了缓存命中率本身,底层算子的实现效率也是影响端到端收益的关键因素,后续可以针对命中路径的算子做定向优化。
纯 GPU 命中场景下有一点点负收益(异步写入的开销),所以在 prefix 命中率不高的场景下不建议开启。但在输入存在大量语义重复的真实场景——Agent 对话、代码库分析、智能客服、文档批量处理——命中率通常很高,收益非常明显。
交互流程
小结
这个项目本质上做了一件事:把 CPU DRAM 当成 HBM 的二级缓存,在 vLLM V1 的 KVConnector 扩展点上实现了节点级的 Prefix Cache 共享。
回顾下来,几个比较关键的选择是:
- 控制面与数据面分离——Scheduler 管决策,Worker 管执行,MetadataServer 管全局状态,职责边界清晰,出问题也容易定位。
- 两阶段缓存提交——先分配空间,等数据写完再标记可用。这个简单的设计避免了”命中到脏数据”的致命问题。
- 逐层流水线加载——不等到所有层就绪再开始 forward,最大程度降低 swap-in 对 TTFT 的冲击。
- 命中增益阈值——不是命中就搬,而是命中”赚得够多”才搬,避免小粒度搬运得不偿失。
当然,如果 prefix 命中率本身很低,CPU Offloading 的异步写入开销就是纯负收益,不建议无脑开启。它最适合的场景是输入中有大量稳定、可复用的语义前缀——而这恰好是 Agent 和 RAG 时代越来越普遍的负载特征。
笔者贡献
我有幸深度参与了 vLLM-Ascend CPU Offloading 特性的完整研发周期,主要贡献如下:
方案设计与讨论:参与了 CPU Offloading 整体方案的技术讨论和评审,包括节点级 Prefix Cache 的共享边界设计、CPU/NPU 数据通路的异步流水线方案、命中增益阈值的策略建模,以及与 MetadataServer 的接口协议定义。在方案迭代过程中推动了两阶段缓存提交机制和逐层 swap-in 流水线的落地,前者从设计上杜绝了”命中脏数据”的一致性问题,后者有效控制了 swap-in 对 TTFT 的延迟冲击。
收益测试与性能分析:独立设计并实现了三段式数据集构造方法和 benchmark 重复发送策略(sequential / stack / reverse),能够灵活构造 0% 到 100% 之间多种 GPU/CPU 命中率组合,填补了 vLLM 原生 benchmark 在复杂命中场景下的测试空白。基于该工具完成了全场景性能收益测试,在 DeepSeek 模型上系统性验证了 CPU Offloading 的有效性边界。此外,通过 profiling 深入分析发现 GQA KV Cache 在 prefix 命中场景下存在算子性能瓶颈,为后续性能优化指明了方向。以上工作为方案的合并决策和适用场景推荐提供了关键数据支撑。
稳定性修复:排查并修复了 profile_run() 显存估算偏差的隐蔽 bug——该问题在特定大并发场景下导致显存超分、进程卡死,定位难度较大。根因是 is_kv_consumer 判断逻辑导致 KVConnector 场景下的剩余显存估算偏高,修复为 not is_kv_producer 后显存估算与实际的 KV Cache 分配行为对齐,消除了此场景下的稳定性隐患。
注:随着 vLLM 主仓在后续版本中原生支持了 CPU Offloading,vLLM-Ascend 中的 CPU Offloading 插件已从代码库中移除,相关能力由主仓统一提供。本文记录的方案设计、工程踩坑和性能分析经验,对理解 vLLM KVConnector 扩展机制和异构缓存系统设计仍有一定参考价值。